- update at 2024-01-20 ‘I/O using cin and cout’
- update at 2024-01-17 ‘优化排版,补充了部分关于c++20 ranges库的简介’
- update at 2022-08-27 ‘重写了部分代码实例,以及补充了部分内容’
- update at 2022-04-25 ‘关于auto和bool的一个问题’
- update at 2022-05-21 ‘accumulate返回值类型的细节’
- update at 2022-05-23 ‘增加了bit部分的内容’
内容未完,之后写代码过程中见到或者想到的好的技巧都会逐步添加。
尽量只使用宏:
| |
参考
常见容器
stringarray-vector-dequemap-multimap-unordered_mapset-multiset-unordered_setstack-queue-prority_queuepair-tuplebitset
支持顺序访问(或迭代器使用std::next,std::prev顺序访问)的容器可以用下面的办法快速枚举:
| |
对于结构体,一定程度上可以使用tuple代替。
两者在访问时都可以使用auto对其结构化绑定声明,语法大概如下:
| |
上面两种可以协同使用,结构化遍历vector<tuple<...>>
但如果仅仅是需要结构化绑定,也可以使用std::tie()替代:
| |
在编译器版本无法支持上述写法的时候,这不失为一种增强代码可读性的方法。
可以见,std::tie()这种写法并非变量声明,而是赋值。
关于Range-based for loop的一些问题
- 使用
for (auto val : v)确实会发生拷贝,但并不是说v中元素就一定不会改变
| |
不过,会出现上面情况的应该也就是vector<bool>这个奇葩了。显然auto判断类型为_Bit_reference,通过下面代码可以验证:
| |
同时,如果你使用了auto &val : v,那么你将面临下面的报错:
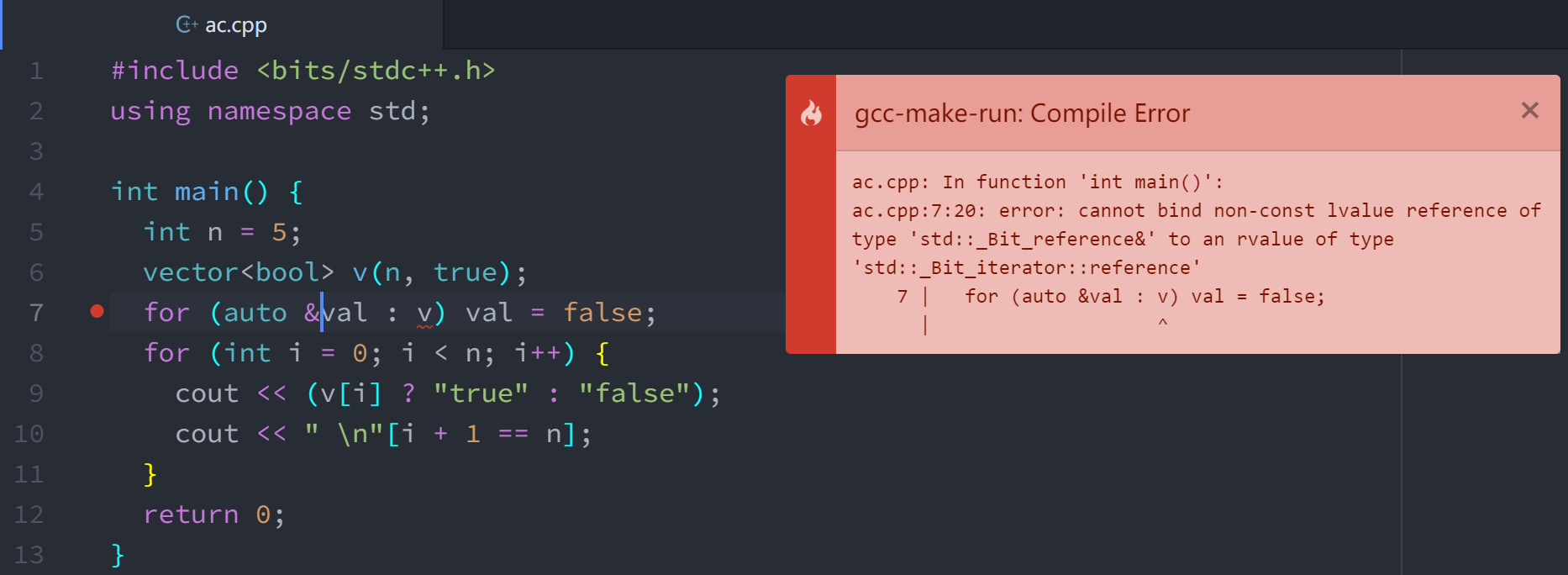
- 如果想用
auto自动识别变量类型的引用,但又不想出错,你应当使用auto &&val : v来代替。 - 使用
const auto &val : v来彻底避免内存拷贝以及保证元素不被修改。
迭代器 与 all()宏
| |
在c++的STL中,更常用的是迭代器,而非下标(指针),这与纯C写法有较大区别。
begin(),end()作为容器的起始迭代器和末尾的迭代器。rbegin(),rend()逆向的迭代器。
对于正序的迭代器,你可能会看见如下的两种用法:
| |
但像rbegin(),rend()则需要到c++14。不过事实上这种写法不太常见,
通常是由于sort默认从小到大排序,但实际需求为从大到小(恰相反,因此反序即可)。
| |
用于遍历的函数如下(虽然有许多容器的迭代器重载了++和--,可以直接像下标一样处理,但还是推荐):
| |
定义这个宏的原因是:使用算法库的函数经常需要填写迭代器范围。
国内这些竞赛平台对于C++语言标准的支持普遍是C++11到17,且gcc和clang目前(2024-01-17)都未有标准库能够完全支持C++20。不过,目前 Codeforce 和 AtCoder 所提供的c++20提交选项已经能够部分支持ranges库了。这意味着,你可以写出:
| |
算法库
此处仅记录一些本人常用的部分,事实上<algorithm>内容十分丰富,并且还在随版本更新。Cpp对于并行优化的支持也逐渐完善,出现了<ranges>这种十分方便的库。一些类似MATLAB的矢量化结构也有望加入到C++26的标准之中,感兴趣的可以观看CppCon 2023的一个分享:std::linalg: Linear Algebra Coming to Standard C++ - Mark Hoemmen。
惟愿本文能抛砖引玉,引起读者的兴趣。参阅 cppreference - algorithm。
排序 std::sort
std::sort(),应该是一个很常见的函数,用来排序数组的时,一些偏向C的写法会使用头尾指针来确定范围,再写外部函数确定排序规则。
但是,在使用如vector等可以排序的容器时,我们一般会动态开空间,所以此时待排序的范围就是全部元素。(或者对起始和终止的迭代器进行运算,以获得合适的排序范围)
| |
与std::sort比较相似的还有std::stable_sort,后者是能够保证,相同大小的元素在排序前后的相对位置不变。
- 检验数组是否有序:
std::is_sorted()
关于 lambda 表达式 (c++11)
在sort函数中,第三个参数可以为我们定义的排序规则,如果不使用lambda表达式,我们往往会把它们写在外面,然后填写函数指针。
lambda表达式,受篇幅限制这里无法展开,建议访问cpp手册 - lambda表达式。基础语法如下:
| |
放在sort中使用的实例:
| |
更多的,如果关联使用<functional>,可以将外部函数写在主函数内。
- 这里还有一个问题,那就是如何写递归函数?
使用 function 类是一种解决办法,如下面的dfs代码:
| |
如果不按照function类来声明该函数,[ captures ]无法获知自己的存在,所以一个可行的方案就是,在传值的时候将自己传入。
| |
按照某些人的说法,使用第二种方式(也就是将“自己”传入)会有更好的性能,理由是更容易获得内联优化。笔者对此持怀疑态度,但也并未验证,仅凭个人经验,这两种方式至少不会出现较大的性能方面的差异。如有读者验证过,不妨在评论中或者以其它方式告知。
搜索相关
我们知道,对于有序容器,我们可以利用其单调性来进行二分。
- 进行了上面的排序操作,我们的数组(暂且这么称呼)已经变得有序,如何利用
STL中写好的二分函数呢?
对于一般容器而言,二分函数的写法比较统一(以vector<int> a为例好了):
| |
对于map,set,这类使用红黑树或者其他非线性数据结构实现的容器,如果你直接按照上面的写法二分,那么时间复杂度将直接退化到$\mathcal{O}(n)$。
正确的使用方法是直接调用其内部封装好的二分函数:
| |
更一般的情况是,我们只需要数组中最值。
| |
- 如果你需要知道是一个数组的第$K$大的数(比如中位数),该怎么办呢,直接排序吗?
在某些时候,我们可能连$\mathcal{O}(n\log n)$的算法也无法接受,
此时可以使用均摊复杂度为$\mathcal{O}(n)$的函数nth_element()
| |
可以见,该函数并非排序,而是将前$K$小的数放在最前面的$K$个位置,且令第$K+1$位上为第$K+1$大。(原理上nth_element()可以使用快速排序的思想完成。实际使用中,需要注意范围左闭右开)
如果仅仅需要一般的查找,使用find或者find_if即可,后者搭配lambda表达式,可以按需搜索。使用时请注意复杂度,对于一般容器,该函数使用的是顺序遍历,时间复杂度为$\mathcal{O}(n)$。若find()查找元素无果,返回的迭代器为end()。特别的,string中find失败得到的是string::npos。
计算相关
count和count_if。
统计元素个数时可用前者 count(all(a), val) ,如果需要按满足条件来统计,使用后者再搭配上lambda表达式即可。值得说明的一点是,map和set中的find和count函数的复杂度是$\mathcal{O}(\log n)$,可以放心使用。
all_ofany_ofnone_of。
顾名思义,对于一个范围,判断满足条件(一般用lambda表达式写)的集合与全集的关系。
partial_sum。
前缀和函数,partial_sum(all(a), begin(b)),此处的 b 需要先开够空间。类似的还有前向差分函数。
accumulate
比较常见的要求是对数组求和,我们直接利用accumulate(all(a), 0)即可,但是该函数还有许多值得探究的部分(cppreference - accumulate)。
注意,在accumulate参数中,求和并非恒定不变,使用lambda表达式或者重载符号+也能够对其修改。
| |
先来阅读两份源码:
- First version
| |
- Second version
| |
上述两份代码均来自 cppreference。可以发现,无论是哪一种,accumulate的返回值类型都不是由数组元素的类型来决定。
所以,一个常犯的错误就是(此处 点名批评 感谢pbrgg提供的素材)
| |
问题何在呢?相信读者应该马上就能反应出来,由于0的类型为int在求和的过程中,结果已经溢出。
Bit相关
这部分主要和c++20标准库头文件<bit>相关,但是考虑到现在许多的编译器还未能完全支持c++20,因此在后面加入了一部分来自GCC Built-in Functions的位操作函数。
c++20 <bit>常用的函数
has_single_bit检查一个数是否为二的整数次幂bit_ceil寻找不小于给定值的最小的二的整数次幂bit_floor寻找不大于给定值的最大的二的整数次幂countl_zero从最高位起计量连续的0位的数量countl_one从最高位起计量连续的1位的数量countr_zero从最低位起计量连续的0位的数量countr_one从最低位起计量连续的1位的数量popcount计量无符号整数中为1的位的数量
bitset 容器
补充一个不怎么常用的容器,bitset本质上就是一个01序列。
其占用内存很小并且也重载了位操作(&, |, >>, <<等)因此有时也用于卡常数。
常用的操作大致如下(以bitset<N> b;为例):
| |
来自GCC Built-in Functions的位操作函数
官方的介绍 https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html
| |
既然写到了gcc的内建函数,不妨也提一下其它的双下划线函数:
__gcd(),顾名思义,一个用于求两数最大公因数的函数。
值得注意的是,在c++17中,已经加入了gcd()函数,可以不加下划线使用。
__builtin_ia32_rdtsc()
rdtsc的原文大概是Read Time Stamp Counter,这个函数原本是用于测量cpu时钟的,用于竞赛大概只能生成随机数种子。所以为什么在这提呢?主要是由于我的随机数生成代码中包含这一个函数。
| |
位运算的其它操作
^异或
对于二值集合{a, b},如何找到不同与x的另一个数呢?,直接if-else判断当然可以,但没必要。最快的写法利用相同数的异或为0,同时任何数与0异或都等于它本身这两个所有人熟知的性质,写成x ^ a ^ b就可以了。
- 二进制枚举
主要是在dfs由数组确定的集合时用到,当然直接写dfs也是可行的,甚至更快。(但,私以为二进制枚举最优雅)
- 取模$2^k$
等价为 & 上 $2^k-1$。用法大概是,最后 & 一下就行(大概。
注意,$2^{32}-1$需要int64_t。此时用uint32_t自然可以,但是会比有符号的慢。
lowbit,submask enumeration等需要在具体的数据结构和算法中使用的技巧,这里就不展开介绍了,可参考如下链接或者自行去OI-Wiki查询。
更多信息可参阅 Bit manipulation - Algorithms for Competitive Programming
I/O相关
I/O在竞赛中的影响其实不算大,虽说某些“歪门邪道”对于卡常数十分执着,但这毕竟不是竞赛所考核的重点。
但是,由于语言特性的关系,某些“语言小白”的代码可能因此从AC变成TLE,这也是本部分独立出来的目的。
同步流
同步流是cpp关于c的兼容性处理。从字面意思上理解,“同步”和“流”就是这一机制的关键。
- cpp的流:
std::cin、std::cout、std::cerr、std::clog以及“宽字符流”的std::wcin、…、std::wclog - c的流:
stdinstdoutstderr
同步流就是让C++流与标准C流在每次输入/输出操作后同步。
| |
不介意警告信息(也不会由编译器报啦,只是写法不太规范的问题)可以写成一行
| |
小白或许会疑惑,为什么下面这行不写?
| |
首先,为什么要cin.tie(nullptr)?在C++中cin和cerr绑定cout,而cout绑定NULL。
所以写cout.tie(nullptr) “字面意义上看,什么都没做”。
绑定会导致流的自动刷新(即cin之前flush一下cout,效果是这样的,但具体实现不详),在竞赛中这是一种奢侈的浪费。
- 关闭了同步流,意味着
scanf/printf,cin/cout等不再同步,C++流拥有自己的同步独立的缓冲区。- 这使得混合C和C++风格的I/O非常危险,所以最好不要混用!!!
std::endl会导致flush,请使用\n换行(事实上理应如此,工程中也建议这样做)。cin.tie(nullptr);+cout << endl;等于白忙活一场且TLE
std::setprecision()等也会导致flush,只要设置一次就好了。- 对于交互题,IO性能完全不用考虑,请不要写
cin.tie(nullptr)。
关闭同步流不是 FAST IO
如上文所述,关闭同步流只是恢复正常,不算快读!真正的快读,你应该自己实现BufferedReader + fread/fwrite
- 如果你是在要,那我只能……偷大佬的板子 Nyaan’s Library - misc/fastio.hpp
浮点数、O2 和 Windows (O.o?)
在 codeforces 你可能会遇到(但是其它使用 Linux 环境评测的不会),浮点数读入和
(2024-01-20 实测Bug无法复现了,悲~) 就当记录历史吧。O2负优化。
- Why std::cin has such a low efficiency when processing float points on Codeforces?
- read doubles faster in cpp
目前,只要不选择 GNU G++17 7.3.0 非64位 的提交选项就不会触发此问题。
| |
在某些有点历史的代码,你可能会看见类似上面这种操作(std::stod()是string -> double的转换函数)。
不要喷他们代码得烂,他们只是遇到了bug(
IO写法技巧
cin.exceptions()如果看我的代码的话,你会发现下面这行:
| |
这是为了捕获读入(类型)错误,其用处是:codeforces交错问题,让它在第一个样例RE(如果读入方式完全一样就认命吧),从而不增加罚时。
注意,这和 while(cin >> ...) 或者 while(scanf(...) != EOF) 的多组输入模式有冲突。原因似乎是,while的终止条件就是 istream::failbit 置位(然后被捕获,触发RE)。
cout << " \n"[i == n];避免行末空格,原理见我的另一篇博客。- 文件I/O,怎么用C++的风格?
- 其实没必要,用
freopen + scanf/printf吧 - 非要用,使用
ifstream/ofstream吧- 什么?你还要
cin/cout? - 那就把
cin.rdbuf()重定向吧。
- 什么?你还要
- 其实没必要,用
如下是一个完整的例子
| |
杂项 与 写法上的技巧
iota(all(a), val)
从val开始递增地赋值,赋值后地数组为 { val, val + 1, ... }。
十分适合用来写并查集的初始化(当然,还有不同的写法是初始化成-1)。
auto [min_val, max_val] = minmax(a, b)
同时获得两数的最大值和最小值,啥用没用 实际使用很少。
低版本建议的写法是 tie(min_val, max_val) = minmax(a, b) ,需要先声明变量。
tie(a, b) = minmax(a, b) 为错误写法!
函数
minmax()的返回值类型为pair<const T &, const T &>。函数
tie(Types&... args)会依次赋值。
那么,如果 $a>b$,则会出现如下的情况:
| |
最后所有的数都变成原先的最小值!
rotate旋转,放在圆(环)上理解可能会好点。
| |
- 求数组中不同元素的个数
| |
next_permutation和prev_permutation
枚举数组的所有排列,常见的写法是:
| |
substr
string中的STL用得比较少,一般使用的就是substr获取子串。
| |
std::vector内存回收问题。举个例子CF1706D2。
对于std::vector而言,pop_back(),clear(),resize()都不会立即回收已经使用过的内存(程序做的应该只是迭代器的移动操作,具体细节本人未作研究,建议读者自行查阅STL的相关源代码)。这大抵是为了方便后续的写入,省去再次分配空间的消耗。要做到立马回收空间,行之有效的方式是,利用std::swap()的机制,将使用的内存交换走。
| |